
今回はスクレイピングに必要な値の取得を中心に実施してみます!
Pythonでどのような動作をするのか検討してみる
今回は値を取得して表示させたいので
Python起動
↓
Yahooニュースのページ表示
↓
トップから5つのニュースを取得する
↓
Pythonに結果を表示させる
このようなシンプルなフローで取得していきたいと思います!
まずは調査をする
ブラウザ起動時に表示するURLを調べる
今回はYahooニュースのトップページから記事を取得したいだけなのでこちらを使用しました。
引用元:Yahooニュース https://news.yahoo.co.jp/

使用したい部品(エレメント)を確認する
作成しながら一つ一つ見ていってもいいですが、全体的に使用するであろう部品(エレメント)は先回りして確認していたほうが効率がいいです。(経験則)これは同一のページにある連続した表示であるから、後ほど紹介するXPathのカスタマイズにも生かされます
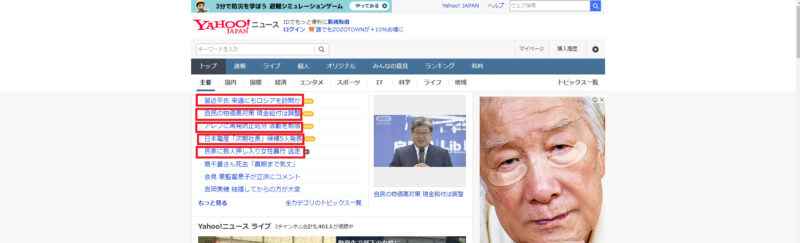
このページの今後の更新を想像してみる
今回はうまくいったとしても更新が入りエラーが表示されてしまっては自動化が失敗してしまいます。
今後の更新を考えてみましょう!
今回のページでは
- 記事数、レイアウトなどの基本構成はしばらくそのままだろうな~
- 今回指定する記事の文面が更新される状態になるんだろうな~
- 更新ごとに取得部品の要素(例えばリンクなど)が変動するんじゃないかな~
と想像しました。
この想像を行うことによって、例えば
//*[text()="ニュース記事の文言"]の指定や
//*[href="https://news.yahoo.co.jp/pickup/XXXXXX"]などの変動する指定をあらかじめ回避することができます。
XPathの抽出
必要となる部品をChromeを使用して抽出してみる
抽出方法は下記記事を参照してみてください

この記事の通り取得すると下記の5つのXPathが取得できました
#1番目
//*[@id="uamods-topics"]/div/div/div/ul/li[1]/a
#2番目
//*[@id="uamods-topics"]/div/div/div/ul/li[2]/a
#3番目
//*[@id="uamods-topics"]/div/div/div/ul/li[3]/a
#4番目
//*[@id="uamods-topics"]/div/div/div/ul/li[4]/a
#5番目
//*[@id="uamods-topics"]/div/div/div/ul/li[5]/aこちらをなんとなく見てみると共通点があったりします
//*[@id="uamods-topics"]/div/div/div/ul/li[表示の順番]/aな表記になっています。このまま使用しても結構いい感じかと思いますが、よりエラー(no such element)が出ないように次の項目でXPathのカスタマイズを行います。
カスタマイズをする
XPathを選択するときになるべく範囲を狭めたほうがエラー(no such element)が出にくくなります
まずは一番最後の要素から調べて一意にできそうな要素を調べてみます
<a href="https://news.yahoo.co.jp/pickup/XXXXX" data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:1;" data-ual-gotocontent="true" class="sc-btzYZH kitJFB" data-cl_cl_index="40">ニュース本文</a>調べてみると、下記の要素が使えるかもしれません
data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:1;"ほかの要素も
data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:2;"とかになっていたのでニュース記事ごとの一意の要素になりうると判断しました。実際にSelenium用に記載したXPathが下記となります。
#1つ目の要素
//a[@data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:1;"]
#2つ目の要素
//a[@data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:2;"]
#3つ目の要素
//a[@data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:3;"]
#4つ目の要素
//a[@data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:4;"]
#5つ目の要素
//a[@data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:5;"]今回はこちらで指定しましたが、一番最後の要素で指定できなさそうであれば次の階層
それでもだめそうなら次の階層と続き一意になる要素を探してみてください
だめそうであれば、今回はChromeでXPath自動生成したものを使用しても問題ありません(作成の流れを教えたいため今回はカスタマイズした部品を使用します)
XPathをコードに組み込んでYahooニュースの記事取得を実行してみる
作成段階ではコマンドプロンプトを起動しておき記載するpyファイルをパス指定して実行したほうがいいです。pyファイルをダブルクリックで実行できますが実行中エラーが出てしまうとすぐに閉じてしまいエラーの内容がわからないことになるからです。
no such elementが出てもくじけない

初回はXPathの要素指定をカスタマイズすると「no such element」のエラーが表示されることが多々あります。その場合は切り分けが必要です。私が実施している切り分けは大体こんな感じです。
- @マークで指定している要素をとりあえず削除してみて実行してみる
- //*[@id=”uamods-topics”]/div/div/div/ul/li[5]/a[@id=”hogehoge”] だとしたら
//*[@id=”uamods-topics”]/div/div/div/ul/li[5]/a にしてみる
- //*[@id=”uamods-topics”]/div/div/div/ul/li[5]/a[@id=”hogehoge”] だとしたら
- それでもNGが出るなら上位階層のみにしてみて順に追加してみて実行してみる
- //*[@id=”uamods-topics”]
//*[@id=”uamods-topics”]/div
//*[@id=”uamods-topics”]/div/div のような形でどこで要素が見失っているのか確認する
- //*[@id=”uamods-topics”]
などを指定を変えてみて原因を変えてみます。原因箇所がわかったら大体要素が足りないことが多く要素を追加すれば解決することが多いです(あくまで一例なのでそれ以外の原因もあります。もしお困りであればコメントいただければ解決できるかもしれません)
通しですべて実行できればひとまず完成!
今回このようにコードを記載しました。
from selenium import webdriver
from selenium.webdriver.chrome import service
from selenium.webdriver.common.by import By
import os
#selenium起動動作
#chromedriverを配置したパスを記載する
chromedriver = "C:\autotest\chromedriver.exe"
chrome_service = service.Service(executable_path=chromedriver)
driver = webdriver.Chrome(service=chrome_service)
#初めに起動するURLを記載する
driver.get('https://news.yahoo.co.jp/')
#####NEWSを5つ取得する#####
news_index_1 = driver.find_element(By.XPATH,'//a[@data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:1;"]').text
news_index_2 = driver.find_element(By.XPATH,'//a[@data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:2;"]').text
news_index_3 = driver.find_element(By.XPATH,'//a[@data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:3;"]').text
news_index_4 = driver.find_element(By.XPATH,'//a[@data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:4;"]').text
news_index_5 = driver.find_element(By.XPATH,'//a[@data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:5;"]').text
#####コンソール上に取得した情報を表示させる#####
print("1つ目のニュース\t:\t" + news_index_1)
print("2つ目のニュース\t:\t" + news_index_2)
print("3つ目のニュース\t:\t" + news_index_3)
print("4つ目のニュース\t:\t" + news_index_4)
print("5つ目のニュース\t:\t" + news_index_5)
#####終了処理をする(何かキーが押されるまで終了しない)#####
os.system('PAUSE')selenium起動動作のコードに関しては下記記事をご覧ください

「NEWSを5つ取得する」のブロックでは前項でカスタマイズしたXPathを使用して指定しております
driver.find_element(By.XPATH,'//a[@data-cl-params="_cl_vmodule:tpc_maj;_cl_link:title;_cl_position:1;"]').textの最後に使用している「.text」はそのタグ外に記載されているテキストを指定する意味となります。
取得した値を「news_index_X」に格納しております。
「コンソール上に取得した情報を表示させる」ブロックで取得した値を表示させています。
そして実行してみるとこのような表示ができたことを確認できております。

最後に
いかがでしたでしょうか?今回は値を使用して表示させる動作をレクチャしました。これを使用することによりデータ収集することが可能となります。
スクレイピングの第一歩としてぜひご覧のPCで実行してみてください!


コメント