
どんなときに使用する?
Webにあるボタンやテキストフォームなどの位置を特定するための要素として使用するときの指定方法として、文言(text)、CSSセレクタ(CSS)、HTMLに含まれているID属性(id)などが選択できますがその中でも異彩を放っているのがXPathです。普段はtextやidなどで指定すればいいのですが、中にはそれでは指定できないような要素が登場する時があります。そのときに役に立つのがXPathとなります。指定方法は下記のような形となり
find_element_by_xpath(hogehoge)hogehogeとしている部分に今回のように目的の要素に対して実施(コピー)を張り付ければ指定できます!
実際の使用方法
では実際に取得方法をスクショを用いて説明します。
サンプルとしてこのブログを用意しました。今回1つの記事をXPathを取得する対象とします
※赤く枠を囲った箇所となります
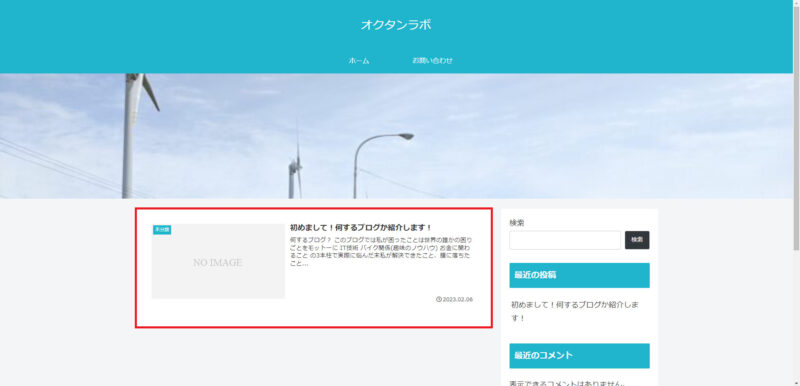
①まず対象とする箇所にマウスカーソルを持って行き右クリックをします
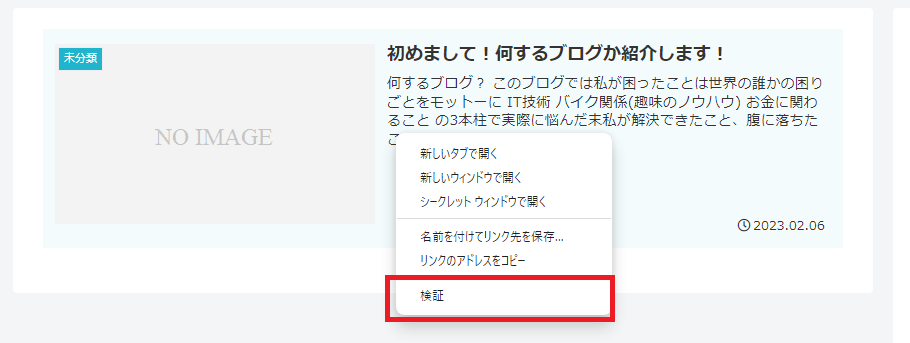
②右クリックするとメニューが出てきます。そこから「検証」を選択します
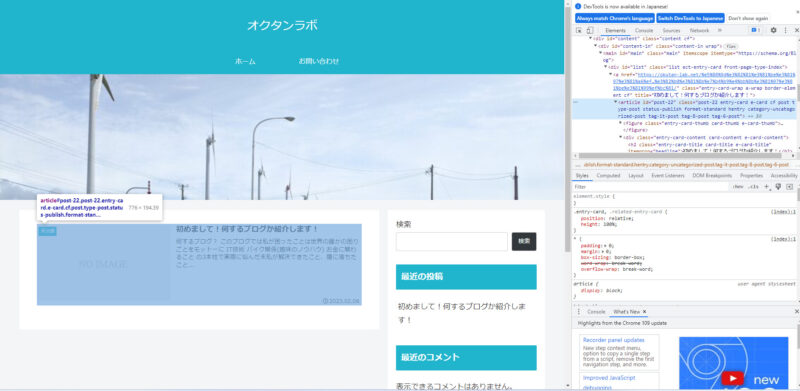
③画面右上側にコードが表示され検証とした箇所がハイライトされます

※ちなみにハイライトされたコードにマウスカーソルをあてるとそのコードがどこにあるかをページをハイライトして教えてくれます
④右側のハイライトされているコードから右クリックをして「Copy」→「Copy XPath」を選択します
(ChromeBookでは「Copy XPath」は日本語表記となっていたので機種ごとに読み替えてください)
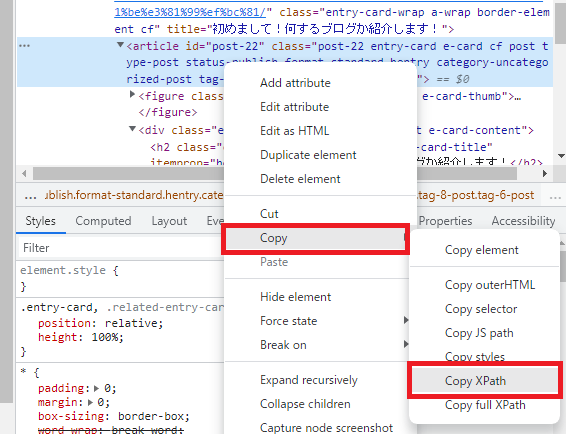
⑤コピーされたのを確認するためテキストエディタに張り付けてみます。今回はこのブログに直に張り付けてみます
//*[@id="post-22"]無事目的のXPathがコピーされていました。コピーされたXPathについての意味は別の機会にお話ししたいと思います。
最後に
いかがでしたでしょうか?簡単にWebページのXPathを取得することがで来ましたでしょうか?
今回のXPathの要素は比較的簡単な部類でしたがこれがidなどの指定がない個所を指定したい場合はものすごい長文が出力されることがよく発生しメンテナンス性を損ねます。それに限らず、XPathはそのまま使用すると取得した直後は問題なく動きますが、少しでもページの改変があると要素がないよとエラーを出して終了してしまうことが多々発生します。しかし、XPathはほかの要素指定よりも柔軟に対応できるポテンシャルを秘めています。今回は初めてXPathを取得する人向けに記載をしましたがこれができるようになった次のステップとして様々な指定方法をお伝えできればと思いまます。

コメント